
Conduit 0.2 is here! A data movement tool is only as good as the number of systems it can support. We’ve all seen large production environments that have many different data stores from the standard relational databases, like PostgreSQL and MySQL, to event monitoring systems, like Prometheus, and everything in between. For this reason, being able to build connectors to meet the needs of your production environments and data stores is critical. In this release, Conduit now has an official SDK that will allow developers to build connectors for any data store.
The second problem that this release sets to tackle is helping developers migrate from legacy systems to Conduit. Swapping out a critical piece of infrastructure is something that isn’t taken lightly. Systems are usually swapped out in pieces to understand the performance characteristics to help minimize downtime and minimize impact to downstream systems. Conduit 0.2 ships with the ability to leverage your current Kafka Connect connectors. This will enable you to use your current Kafka Connect connectors while using Conduit under the hood. The benefit is you can transition to an official Conduit connector on a timeline that works for you.
A Simple Connector Lifecycle
Building your own connector starts with theConduit Connector SDK and deciding on whether you need your connector to pull data from a data source, push data to a data source, or possibly both. One of the design goals of the SDK was to make the implementation of connectors as simple and painless as possible. For example, let’s assume you want to build a connector that subscribed to a channel in Redis. The Redis connector would only need to implement four functions to be full-featured. Each function has a purpose in the connector lifecycle.
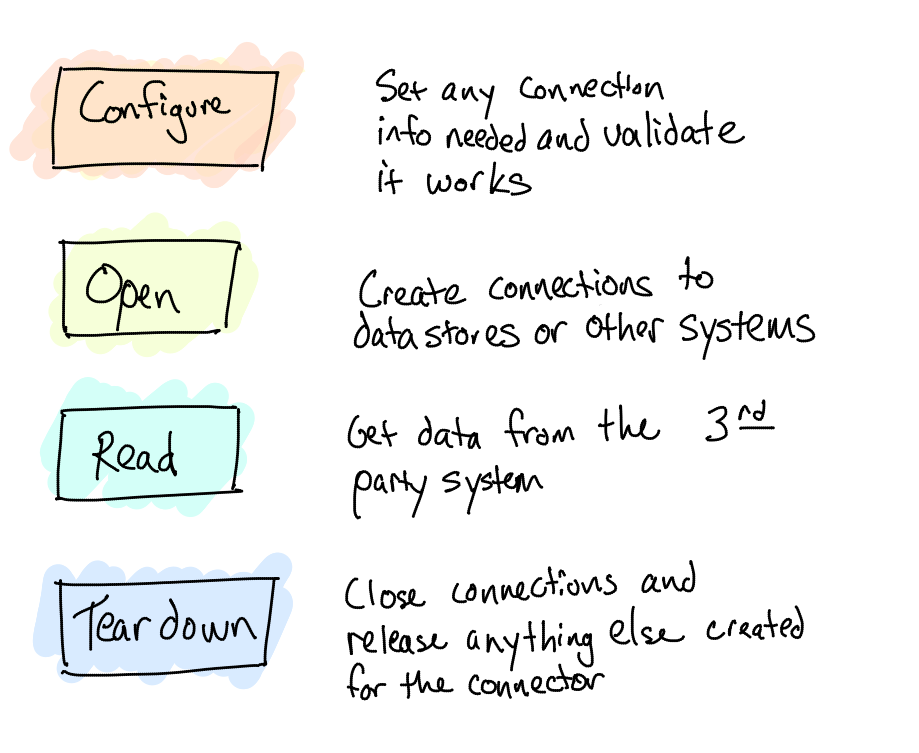
Conduit Connector Lifecycle
That’s it! With these four methods, a connector can be created and you can start moving data between any of the other Conduit connectors. For more details, make sure to checkoutthe ADR for the system on GitHub.
Easing the Transition from Kafka Connect
Changing backends when you’re dealing with high-velocity data has two challenges. The first is performing a migration while data is still being produced by upstream systems and the second is subtle changes in connector behaviors between the legacy system and the new one. To avoid these challenges, Conduit allows the operator to change the underlying system without having to worry about changes in connector behavior. This allows you to make the migration and preserve the investment you may have made in building custom Kafka Connect connectors. This allows operators to explore the benefits of using Conduit in their staging and production environments without having to get the entire engineering team involved to make changes to upstream or downstream systems. It’s a win-win for all!
To get started, all you need to do is download the Kafka Connect package you want to use for your datastore and point Conduit to it. All of the settings you would have needed to pass to your Kafka Connect connector can pass through via the Conduit setup.
Let’s assume Conduit is set up on your machine using the standard setup and you already have an empty pipeline ready to go: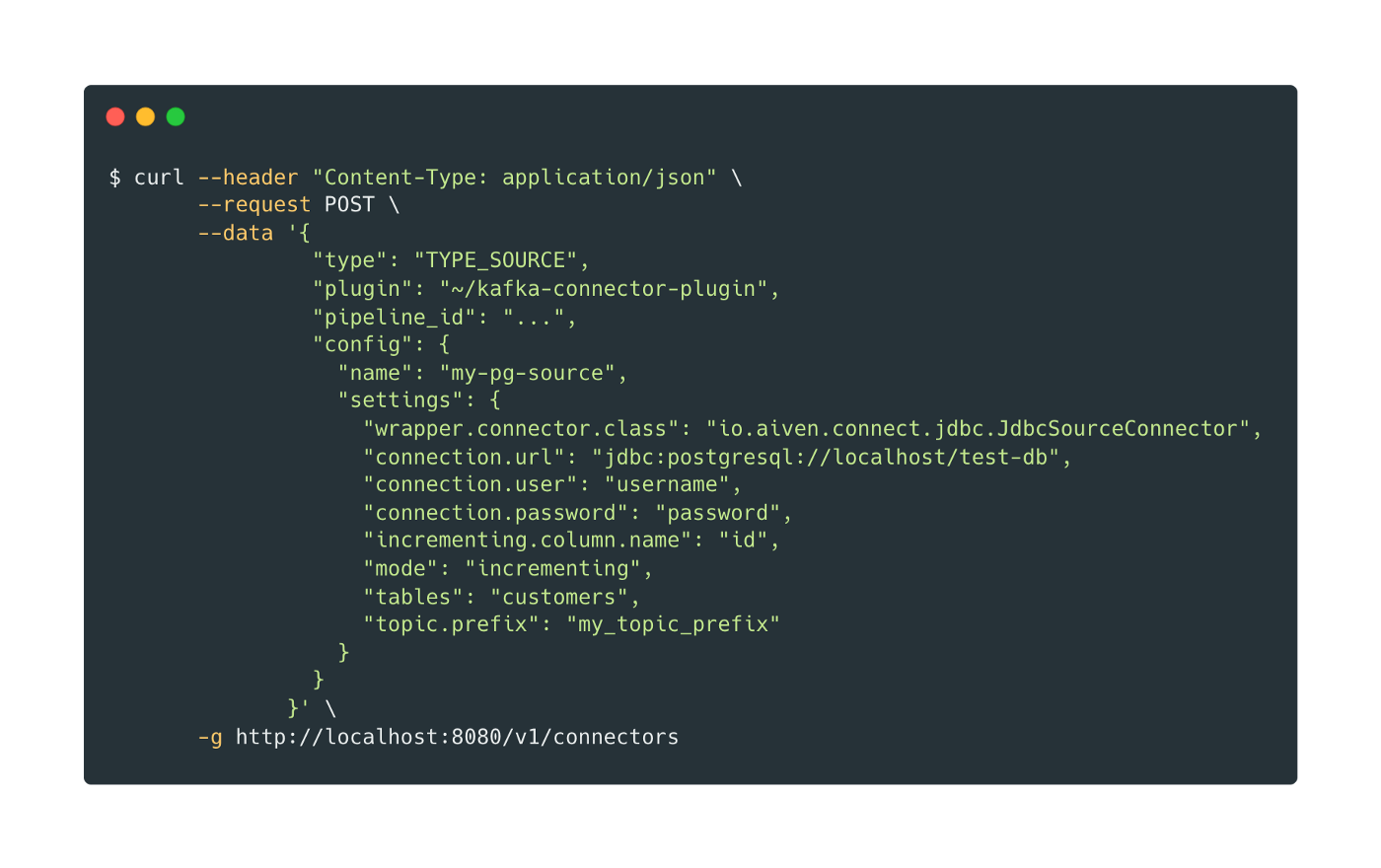 That’s a lot of settings! In the example above, the keys that start with `wrapper.*` are specific to the Conduit setup. The rest of the settings are for the Kafka Connect connector. Any setting name that you would have used in Kafka Connect will pass through, no need to do anything different.
That’s a lot of settings! In the example above, the keys that start with `wrapper.*` are specific to the Conduit setup. The rest of the settings are for the Kafka Connect connector. Any setting name that you would have used in Kafka Connect will pass through, no need to do anything different.
Check Out the Rest
Creating connectors represents only a portion of what we released for Conduit 0.2. For all of the changes, make sure to check out the changelog on the releases page for 0.2. Join us on GitHub Discussions or Discord for any questions or feedback on where we’re taking Conduit.



