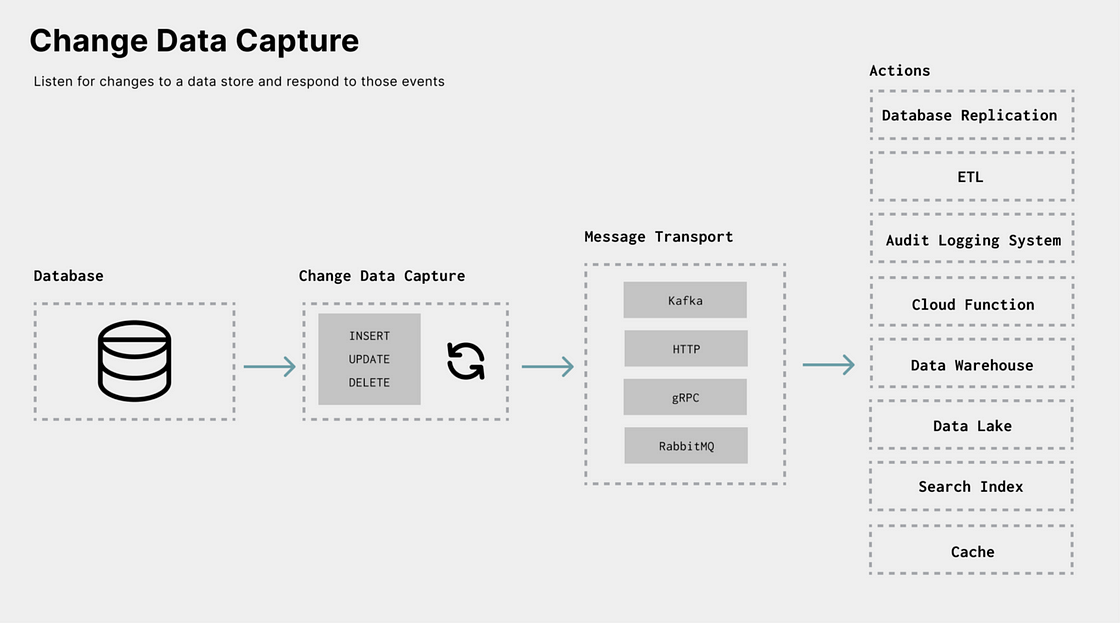
What is Change Data Capture?
Change Data Capture (CDC) is a general term for a mechanism that communicates not just the current state of some data in an upstream resource, but the actual operation that caused the change in that data.
Consider the case of traditional (non-CDC) data integration, where we have a pipeline that is pulling records from a Postgres operation database at some regular interval. In this case, what you end up with is a series of snapshots of what the database looked like whenever that particular interval lands.
A small improvement would be incremental syncing, where we look only for new records and pull those instead of every record each time. This is surely better since it is (generally) magnitudes more efficient.
However, CDC can improve this further by not only providing new records but any record that was changed and it will also update details around the operation that triggered the change. An example of this would be we have a record that was updated (i.e. a single field was updated with a new value). CDC can provide additional metadata indicating that the record was an update and depending on the resource/tooling can even capture the before and after states, highlighting the exact change.
It’s clear that CDC provides numerous advantages, so why isn’t it used everywhere for everything?

Kafka Connect and CDC Right now
We can’t really discuss CDC without talking aboutDebezium. Debezium is the umbrella project for a collection of Kafka Connect connectors focused on CDC maintained by the team at Red Hat.
In our opinion, the Debezium connectors are excellent. They’re well designed, battle-tested, and well documented.
Here’s an example of a CDC record from the Debezium Postgres Source Connector:
{
"schema": { ... },
"payload": {
"before": {
"id": 1,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "oldemail@example.com"
},
"after": {
"id": 1,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "newemail@example.com"
},
"source": {
"version": "2.0.0.Alpha1",
"connector": "postgresql",
"name": "PostgreSQL_server",
"ts_ms": 1559033904863,
"snapshot": false,
"db": "postgres",
"schema": "public",
"table": "customers",
"txId": 556,
"lsn": 24023128,
"xmin": null
},
"op": "u",
"ts_ms": 1465584025523
}
}In this example, a user’s email has been updated in-place, so anupdaterecord (“op”: “u”) was emitted showing the previous email (oldemail@example.com) and the new one (newemail@example.com).
Using the Debezium connectors, you can build downstream apps that consume this data and intelligently act on each type of operation.
Where things start to fall apart is once you start looking into the sink (or destination) side of data integration. Very few Kafka Connect sink connectors can take advantage of the CDC data provided by the Debezium connectors.
In many cases you’re forced to use a providedtransform to “unwrap” the records (effectively stripping away all of the CDC data), leaving only the final (”after”) state of the record.
The practical implications of this are you lose the ability to map updates and deletes and are often left with append-only style inserts.
Here’s what the previous CDC record looks like after it has beenunwrapped so that it can be pushed down to sink connectors:
{
"schema": { ... },
"payload": {
"id": 1,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "newemail@example.com"
}
}What’s the ideal situation?
Ideally,all sink/destination connectors will supportall CDC operations and map them to whatever makes sense for the resource. If the resource can support updates, then update the correct record. If it can’t, you can create a new record with the operation included as a field.
This way resources such as operational databases can be kept in sync (with updates and deletes being applied) and append-only behavior (if desired e.g. for compliance) can still be enforced but optionally at the sink instead.
What is OpenCDC?
In order to move the community toward the goal of ubiquitous CDC interoperability, Meroxa is proposing at least initially a set of guidelines under the project name OpenCDC.
Specifically, we’re advocating for standardizing on a minimal set of CDC operations loosely based on those introduced by the Debezium connectors:
- Create (
c) - Newly created records - Read (
r) - Records read as part of a snapshot - Update (
u) - Records that have been updated - Delete (
d) - Records that have been deleted
The above list provides a base starting point. There are compelling arguments for supporting (and distinguishing) additional operations such as DDL operates and/or resource-specific operations such as truncate.
What’s Next
We want to shape these guidelines based on input from the community. If you’re interested in helping to define these guidelines, contact us atinfo@meroxa.com with the subject lineOpenCDC or connect with us onDiscord.
FAQ
- Why “guidelines” and not a standard? Our long-term goal is to ultimately have a standard or specification for OpenCDC, but to get there we first need to land on the set of core operations to support. By starting with guidelines, we’re able to shape these guidelines based on input and feedback from the community.
- Is OpenCDC a format? The term “format” is overloaded in the data integration space and we’re wary of using it in the context of OpenCDC. Ideally, OpenCDC would be a specification for the contents of the OpenCDC record (i.e. the fields themselves and their data types). The actual format would be independent where the record could be encoded into Avro, Protobuf, or JSON.
- Who is involved with this? We’re currently talking to a large (and growing) list of organizations that share our interest in delivering CDC interoperability. If you’re interested in getting involved, please reach out to us atinfo@meroxa.com or jump into ourDiscord server.
- Who “owns” OpenCDC? Our intention is to operate OpenCDC as a community-driven project. Ideally, one that is governed by an established foundation such as the CNCF or similar.




